
 +100宝石
+100宝石

加入 Mergeek 福利群
扫码添加小助手,精彩福利不错过!
若不方便扫码,请在 Mergeek 公众号,回复 群 即可加入
- 精品限免
- 早鸟优惠
- 众测送码

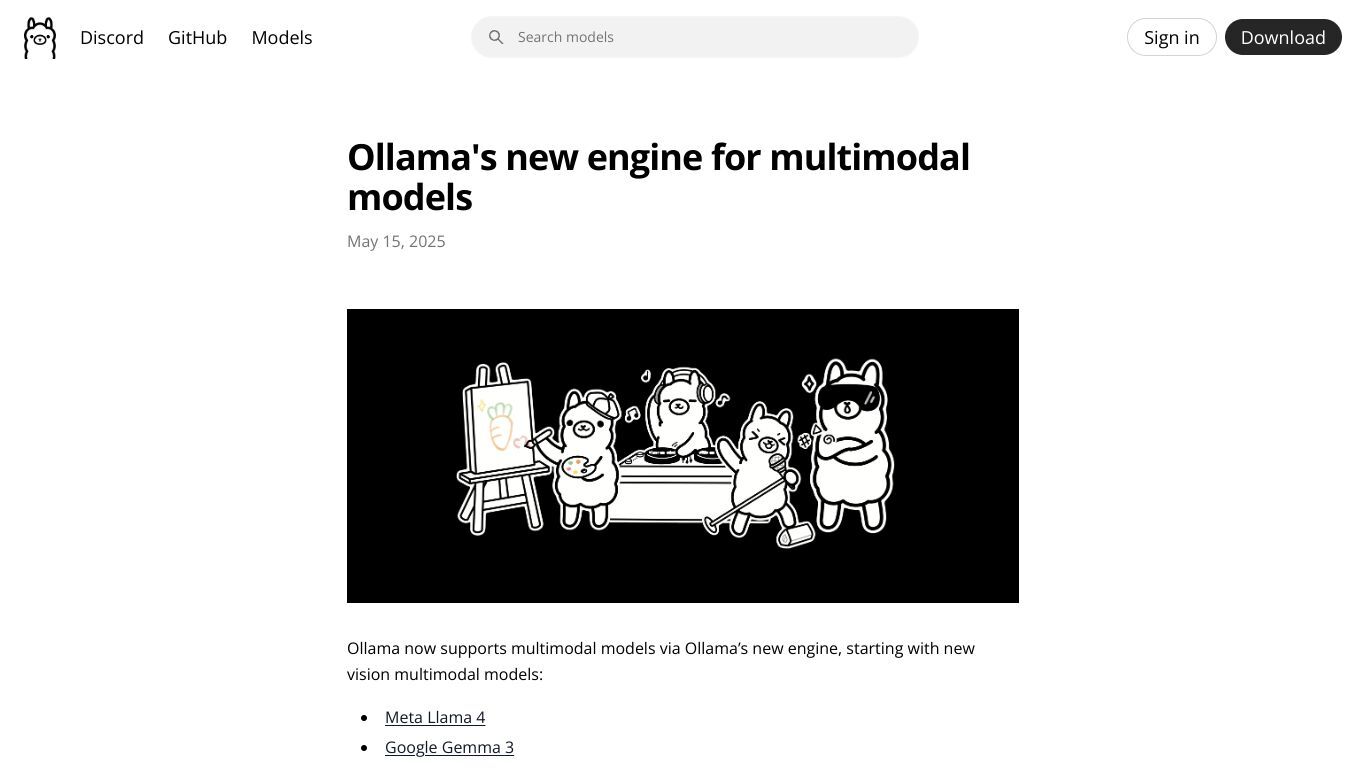
Ollama's new engine
多模态交互,高效转换,Ollama新引擎升级
 分享
分享









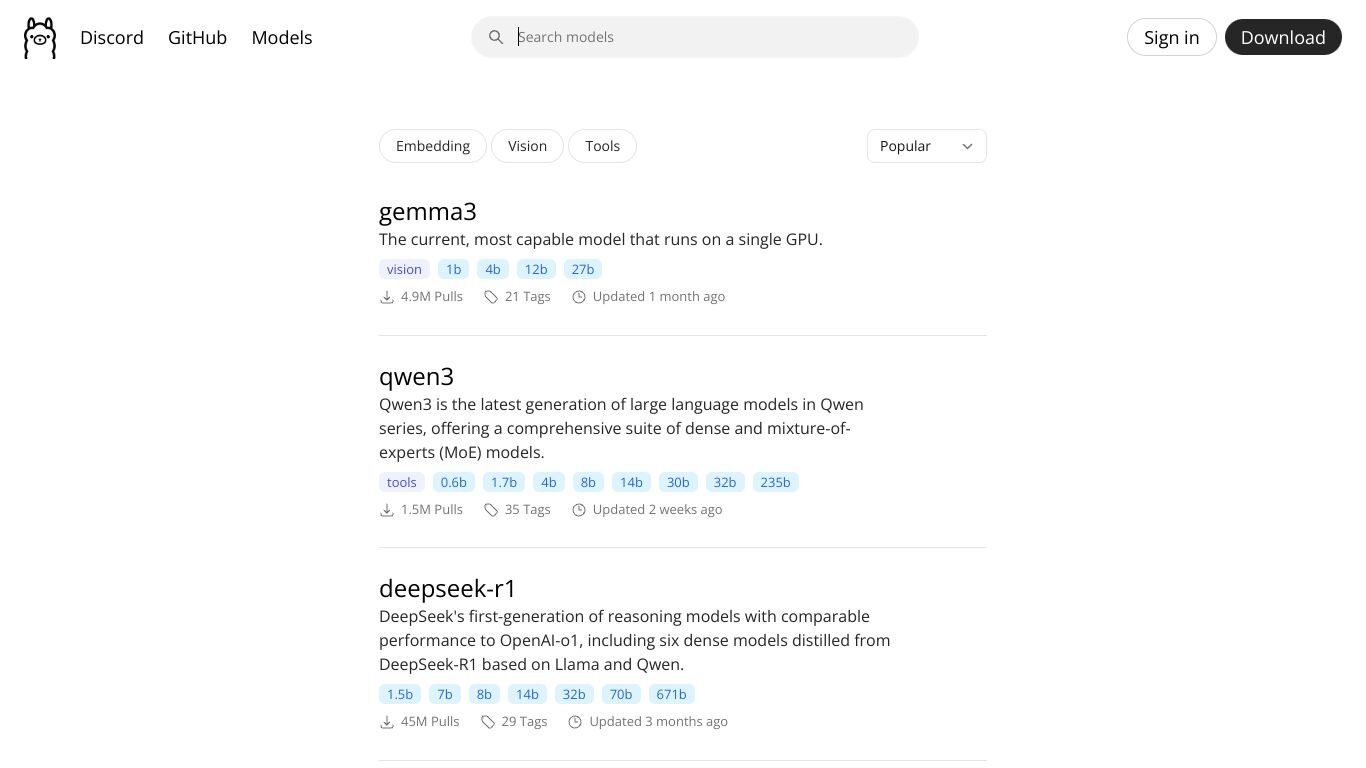
Ollama现支持多模态模型,集成先进AI技术,实现文本、语音、图像等信息的无缝转换与交互。Meta Llama 4提供视觉多模态理解,支持基于位置的提问;General Multimodal Understanding & Reasoning支持多模态理解与推理;Qwen 2.5 VL提供视觉语言模型;Mistral Small 3.1增强视觉与长文本处理能力;Llama 4 Scout具备视觉理解能力。Gemma 3支持多图像关系分析;Qwen3提供大型语言模型,含MoE模型;DeepSeek-R1性能与OpenAI-o1相当。Llama系列提供不同参数规模模型,满足不同资源需求。Nomic-embed-text提供高性能开放嵌入模型,支...






























用户评价
立即分享产品体验
你的真实体验,为其他用户提供宝贵参考
💎 分享获得宝石
【分享体验 · 获得宝石 · 增加抽奖机会】
将你的产品体验分享给更多人,获得更多宝石奖励!
💎 宝石奖励
每当有用户点击你分享的体验链接并点赞"对我有用",你将获得:
🔗 如何分享
复制下方专属链接,分享到社交媒体、群聊或好友:
💡 小贴士
分享时可以添加你的个人推荐语,让更多人了解这款产品的优点!
示例分享文案:
"推荐一款我最近体验过的应用,界面设计很精美,功能也很实用。有兴趣的朋友可以看看我的详细体验评价~"